最近需要使用Matlab进行一些科学计算,但是速度较慢,需要改多线程。由于我对matlab并不是很熟悉,直接改matlab代码使其并行执行难度较大。
于是,我准备使用python去调用命令行matlab实现多线程执行,就可以直接使用我之前写的python多线程模板了!
首先需要给服务器安装matlab,这里可以参考:https://blog.csdn.net/harrype/article/details/135253239,安装完成后,我们就可以使用命令行方式执行matlab代码了。
我的matlab任务是传入两个参数给方法myPoCal,第一个参数是输入的文件位置,第二个参数是计算结果保存的文件位置。具体命令如下:
matlab -nodisplay -nosplash -nodesktop -r "myPoCal /home/jzm/part2_data/jzm_sit_head_1.mkv/mats/0001/000000.mat /home/jzm/part2_data/jzm_sit_head_1.mkv/rcss/0001/000000.mat;exit;"
可以先尝试直接在命令行执行该命令,如果可以运行且正常退出,则可以进行下一步,编写python代码:
import subprocess
import os
import multiprocessing
from queue import Queue
def error_callback(error):
print(f"Error info: {error}")
def job(data):
in_mat = data[0]
out_mat = data[1]
print(f"in_mat: {in_mat}")
print(f"out_mat: {out_mat}")
# Matlab脚本的路径
script_name = "myPoCal"
# 要传递的参数列表
args = [in_mat, out_mat]
# 构建完整的命令字符串
command = f'matlab -nodisplay -nosplash -nodesktop -r "{script_name} {" ".join(args)}; exit;"'
print(command)
try:
# 运行命令
result = subprocess.run(command, shell=True, capture_output=True)
if result.returncode == 0:
print("OK")
# 输出结果(如有)
output = result.stdout.decode('utf-8')
print(f"Output:\n{output}")
else:
print("Error")
except Exception as e:
print(f"Error Msg: {e}")
if __name__ == '__main__':
dir_name = "jzm_squat_1.mkv"
base_dir = "/home/jzm/part2_data/" + dir_name
mats_dir = os.path.join(base_dir,"mats/0001")
rcss_dir = os.path.join(base_dir,"rcss/0001")
if not os.path.exists(rcss_dir):
os.makedirs(rcss_dir)
data_queue = Queue()
for i in range(1200):
data_queue.put((
os.path.join(mats_dir,f"{i:06d}.mat"),
os.path.join(rcss_dir,f"{i:06d}.mat"),
))
num_workers = multiprocessing.cpu_count()
pool = multiprocessing.Pool(num_workers)
while not data_queue.empty():
data = data_queue.get()
pool.apply_async(func=job, args=(data,), error_callback=error_callback)
pool.close() # 不在接收新任务
pool.join() # 主进程阻塞等待子进程的退出,join方法必须在close或terminate之后使用。
print("exit")
这里,每个文件夹中有1200个文件,该python脚本会尝试配置一个和机器相同逻辑cpu数的线程池,将1200个文件依次送入队列,之后使用线程池中的线程对队列中的任务进行消费,直到队列为空。
function myPoCal(in_file,out_file)
global C
global coord nvert modelname symplanes
global ntria facet scale changed
global g_in_file g_out_file
C = 3*10^8; % speed of light in m/sec
g_in_file = in_file;
g_out_file = out_file;
load(g_in_file);
CalcBistat;
end
顺便贴上matlab的代码,方便以后参考。
总结,在使用多线程后 intel i7-12700 从之前处理1200个文件的40h耗时降低到了3h。下面是cpu多线程占用情况:
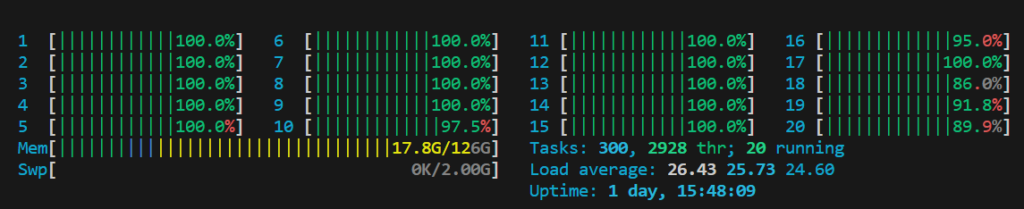
可以看出,基本可以吃满所有逻辑核心。
—2024.01.16—
现在机房有一批8代9代的CPU机器可以用,但是操作系统是windows10,继续使用之前的方法,发现无法使用python线程池去启动,因为python每提交一个matlab命令后不会阻塞等待该命令结束,而是认为该线程完成了任务,又将其扔入空闲线程池,导致内存爆炸。windows matlab 执行原linux上的无GUI启动命令时还是会启动一个窗口Shell程序。
目前解决方法:放弃python,改用matlab parfor,发现parfor没有想象的那末难,简直是开箱即用!
base_dir = "F:\\part2_data";
subjects = ["mcl"];
actions = ["sit_head", "sit_leg"];
samples = ["1","2","3","4","5","6","7","8"];
% 开始并行循环
for sub = 1:length(subjects)
for act = 1:length(actions)
for sam = 1:length(samples)
parfor i = 1:1200
in_file = sprintf("%s\\%s_%s_%s.mkv\\mats\\0001\\%06d.mat",base_dir,subjects(sub),actions(act),samples(sam),i-1);
out_file = sprintf("%s\\%s_%s_%s.mkv\\rcss\\0001\\%06d.mat",base_dir,subjects(sub),actions(act),samples(sam),i-1);
disp(in_file)
disp(out_file)
myPoCal(in_file, out_file);
end
end
end
end
使用 parfor 比 python 方式节省了大量内存,唯一的坑就是 matlab for 循环从1开始且默认闭区间!