








1.写在前面
本次主要是使用Oracle VM VirtualBox多开CentOS进行 模拟集群测试。
2.配置每个节点
1.每个节点都要安装Hadoop-3.1.2。
2.每个节点都要安装并且配置好Java环境。
这里Java我选择直接从Oracle官网下载最新的rpm包然后使用yum直接安装,安装完成后再配置/etc/profile 文件
nano /etc/profile在末尾添加
export JAVA_HOME=/usr/java/jdk1.8.0_201-amd64 export JRE_HOME=$JAVA_HOME/jre export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib export PATH=$JAVA_HOME/bin:$PATH
之后刷新
source /etc/profile此时执行
echo ${JAVA_HOME}出现以下类似结果表示设置正确
![]()
![]()
3.然后对每个节点执行单节点测试
(当然对于上千节点还是在master上配置好后直接分发给slave比较方便)
3.进行集群配置
接下来集群将会根据这张表格进行配置

1.配置hosts
nano /etc/hosts添加如下内容
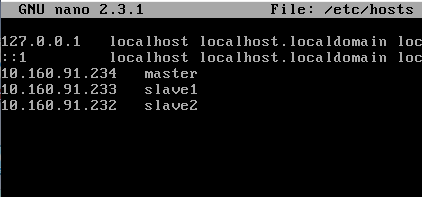
(根据自己机器的IP地址具体情况而定)
【第一次配置时没有去改这个hosts结果配置完成后OverView里有三个节点而Datanode Information只显示一个节点】
2.配置SSH
主要是方便以后群起,群关使用。
生成key(每个节点都需要生成)
ssh-keygen -t rsa一直回车即可
然后在master上copy key 到slave
ssh-copy-id [ip]这里还要在slave1上copy key 到另外两个(因为yarn服务在slave1上)
3.修改Hadoop配置文件
需要配置的文件的位置为/hadoop-2.6.4/etc/hadoop,需要修改的有以下几个
hadoop-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
works
其中
hadoop-env.sh和yarn-env.sh里面都要添加jdk的环境变量。
hadoop-env.sh
# The java implementation to use. By default, this environment
# variable is REQUIRED on ALL platforms except OS X!
# export JAVA_HOME=
export JAVA_HOME=/usr/java/jdk1.8.0_201-amd64
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://10.160.91.234:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop-3.1.2/data/tmp</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>10.160.91.232:50090</value>
</property>
<property>
<name>dfs.namenode.datanode.registration.ip-hostname-check</name>
<value>false</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>10.160.91.234</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>10.160.91.234</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggreation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>10.160.91.233</value>
</property>
</configuration>
works
10.160.91.234
10.160.91.233
10.160.91.232注意:集群配置文件所有机器要保持一致,可以现在master上改好然后用scp分发给slave节点当然也可以使用脚本自动分发
4.启动
在启动之前要进行格式化:
注意:第一次格式化不需要删除data和logs,但是以后每次格式化都要将所有节点上的 data 和 logs 删除
master执行格式化命令:
bin/hdfs namenode –format
1.挨个启动方法
启动namenode命令:
sbin/hadoop-daemon.sh start namenode启动datanode命令:
sbin/hadoop-daemon.sh start datanode启动nodemanager命令:
sbin/yarn-daemon.sh start nodemanager以此类推… …
2.群起方法
在master上启动dfs
sbin/start-dfs.sh在slave1上启动resourcemanger
sbin/start-yarn.sh可以使用jps查看启动情况
下面是我的namenode information和 all application
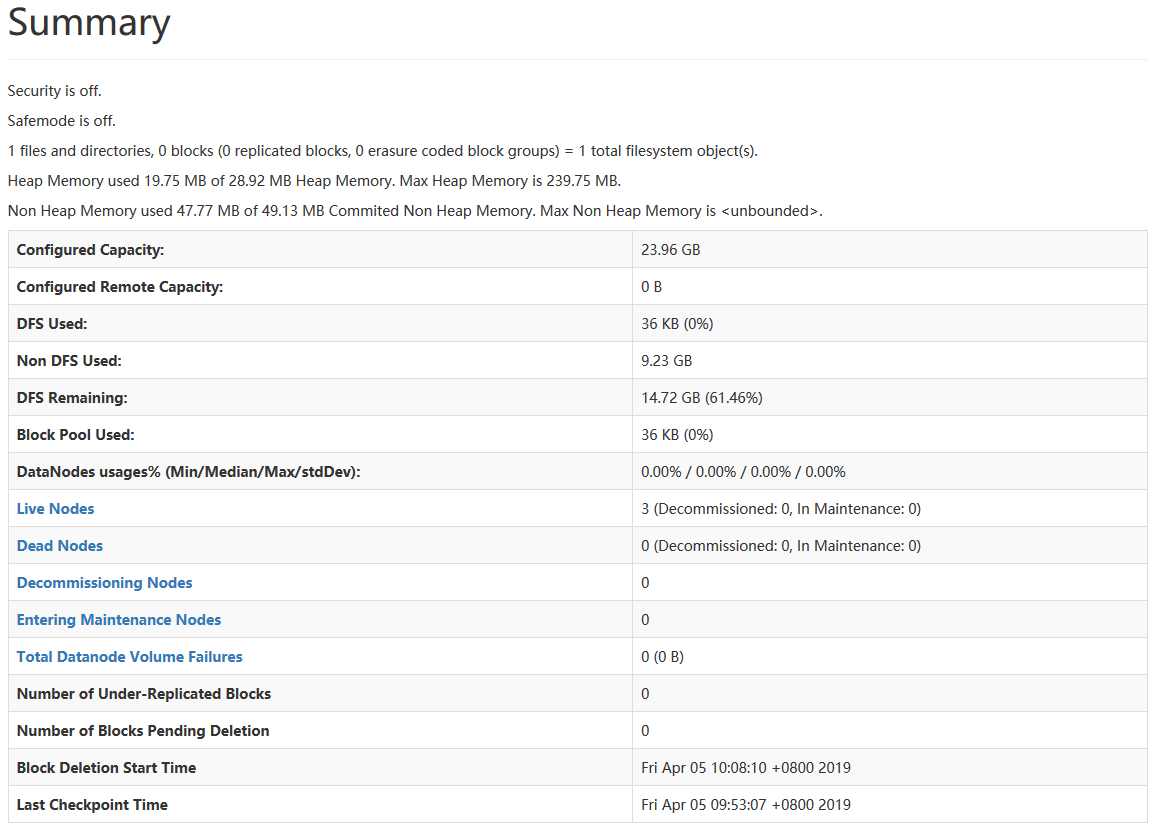
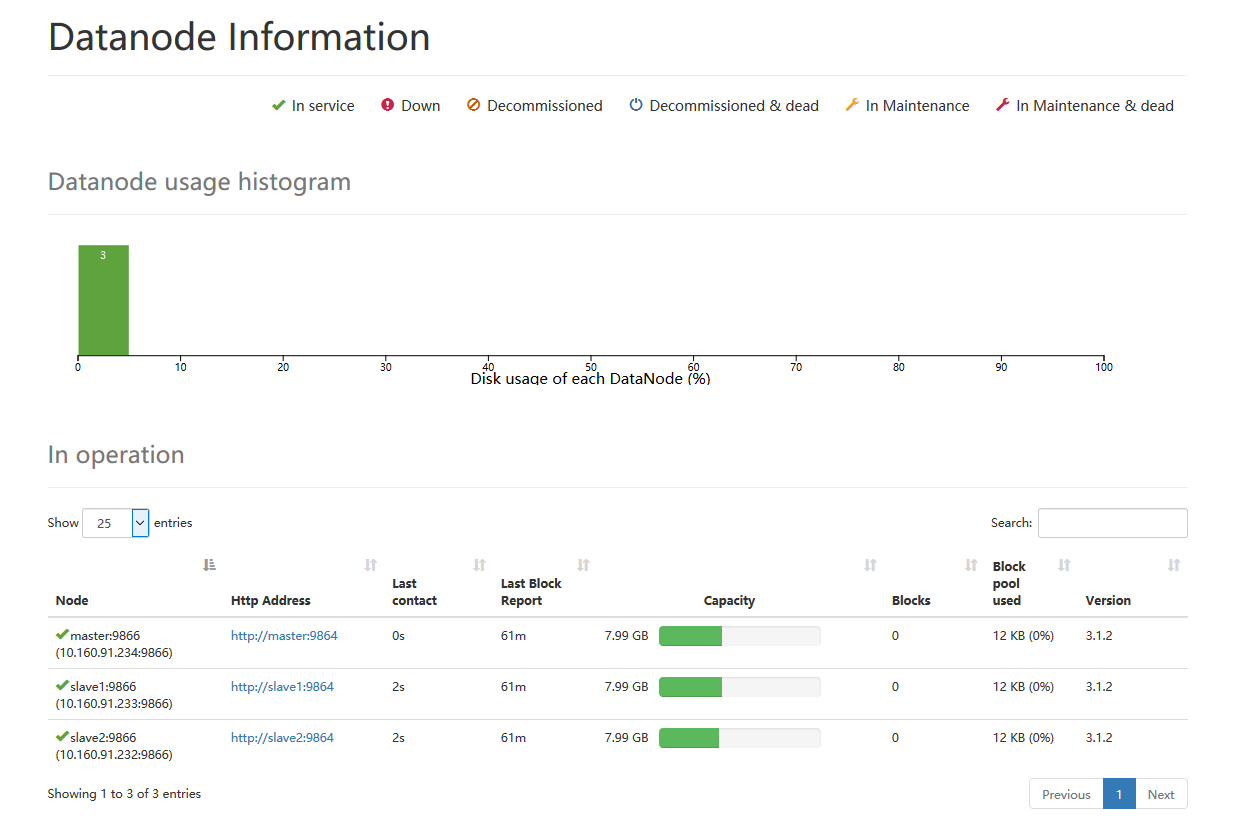
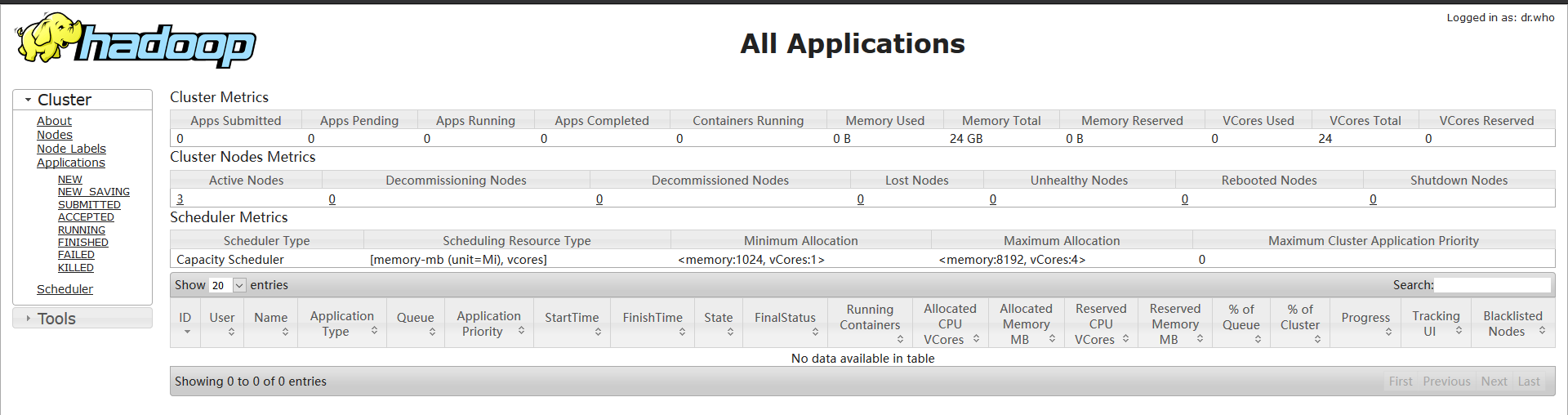
如果你用的时root账户则在群起时会报错
只需根据提示添加相应内容即可
start-yarn.sh
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
start-dfs.sh
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
出现任何错误都可以通过查看日志 logs/ 下的对应文件解决!!!
namenode information地址:http://10.160.91.233:8088
all application地址:http://10.160.91.234:9870