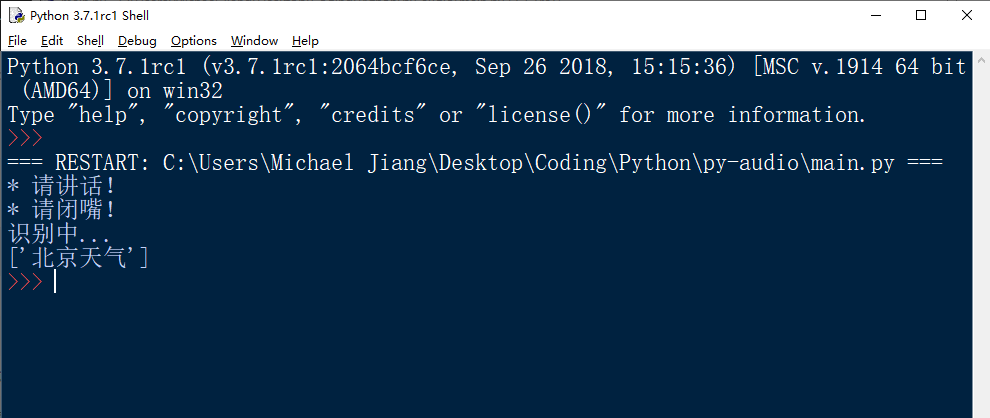
思路:录制本地文件->调用API进行识别->返回结果
首先使用pip安装pyaudio
pip3 install pyaudio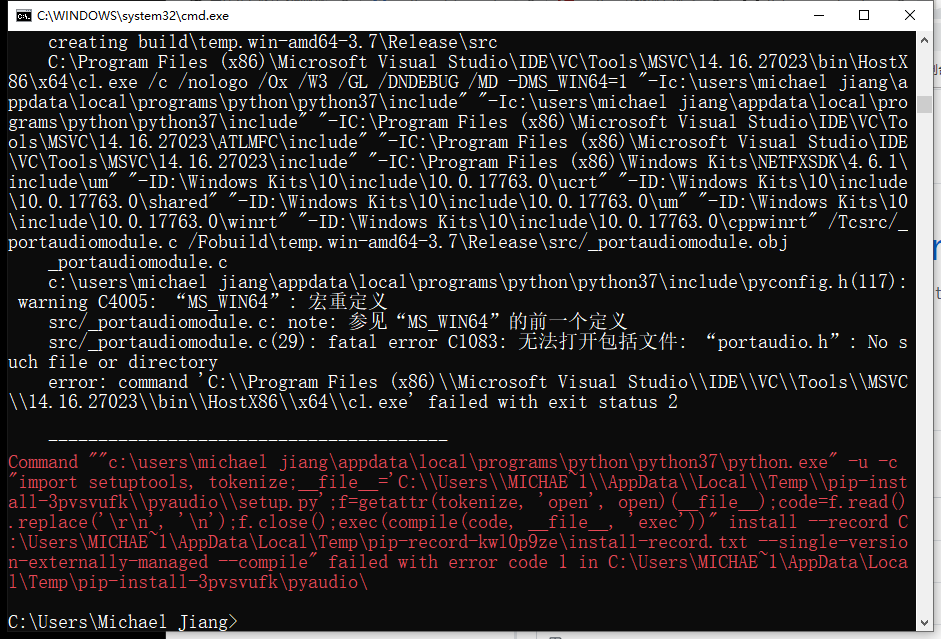
emmm
常规操作
去pypi看一下 https://pypi.org/project/PyAudio/#files
发现pypi目前还没有更新python3.7的pyaudio包
先去网上找一找有没有第三方做过
果然有->https://github.com/intxcc/pyaudio_portaudio
哈哈 还有release版本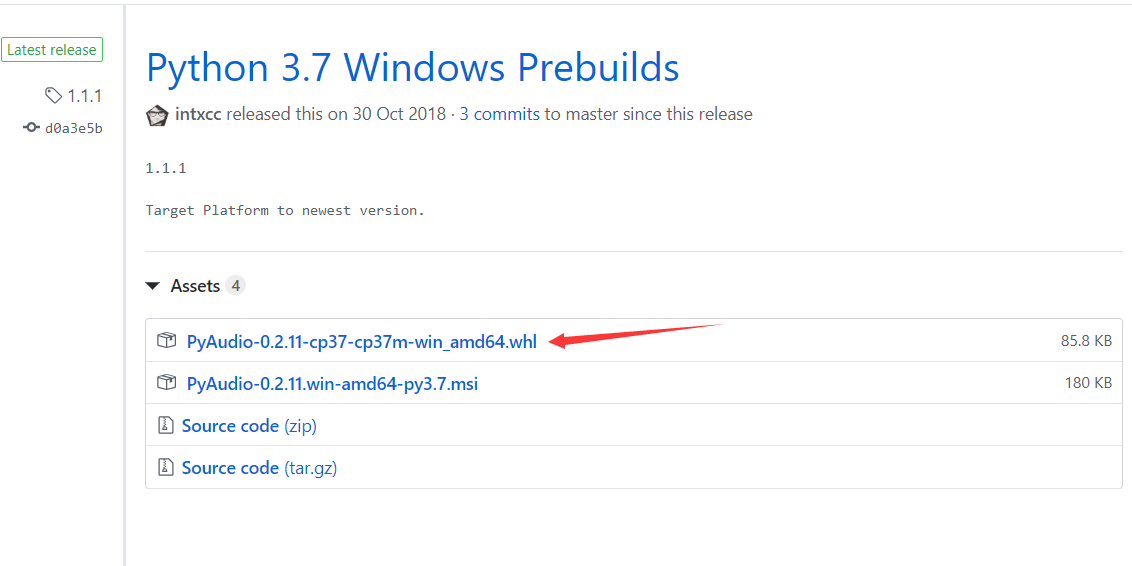
直接下载然后用 pip安装即可!

nice!
官方文档在这里->http://people.csail.mit.edu/hubert/pyaudio/
试一下录音的example吧
import pyaudio
import wave
CHUNK = 1024
FORMAT = pyaudio.paInt16
CHANNELS = 2
RATE = 44100
RECORD_SECONDS = 5
WAVE_OUTPUT_FILENAME = "output.wav"
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
print("* recording")
frames = []
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
print("* done recording")
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
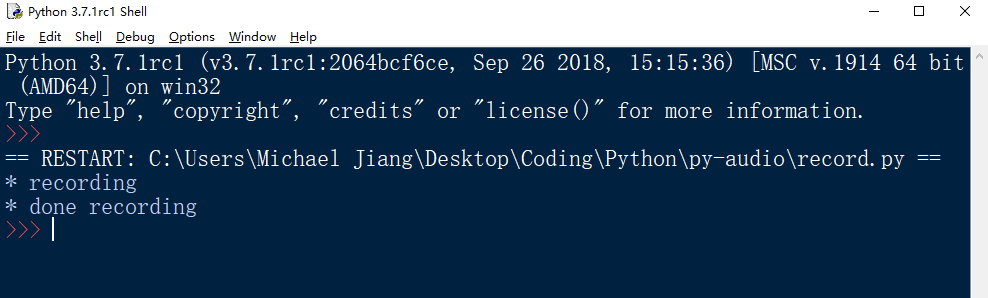
完全没问题!
那么录音没问题了???
当然不是,下图是百度语音识别开发文档

由于使用百度的语音识别api,就必须按照他们的规矩来
因为pyaudio录制的是wav需要转一下;百度开发文档还是很贴心的给出了FFmpeg 的许多转换命令。
wav 文件转 16k 16bits 位深的单声道pcm文件
ffmpeg -y -i 16k.wav -acodec pcm_s16le -f s16le -ac 1 -ar 16000 16k.pcm
44100 采样率 单声道 16bts pcm 文件转 16000采样率 16bits 位深的单声道pcm文件
ffmpeg -y -f s16le -ac 1 -ar 44100 -i test44.pcm -acodec pcm_s16le -f s16le -ac 1 -ar 16000 16k.pcm
mp3 文件转 16K 16bits 位深的单声道 pcm文件
ffmpeg -y -i aidemo.mp3 -acodec pcm_s16le -f s16le -ac 1 -ar 16000 16k.pcm
// -acodec pcm_s16le pcm_s16le 16bits 编码器
// -f s16le 保存为16bits pcm格式
// -ac 1 单声道
// -ar 16000 16000采样率如果你的电脑没有安装ffmeg 请去->http://ffmpeg.org/
安装百度语音的Python包
pip install baidu-aip
没有出现问题(注意使用百度语音需要注册百度开发者【不要钱】)
接下来就是仿照开发文档写一个调用即可!
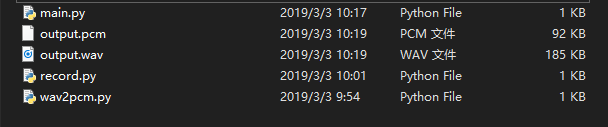
如图我共写了三个py
record.py 主要用来录音(产生一个output.wav)
wav2pcm.py主要是使用FFmpeg进行音频格式转换(output.wav -> output.pcm)
main.py 主要是创建百度语音api客户端然后提交pcm格式语音并从服务器获得识别结果
record.py
import pyaudio
import wave
CHUNK = 1024
FORMAT = pyaudio.paInt16
CHANNELS = 2
RATE = 16000
RECORD_SECONDS = 3
WAVE_OUTPUT_FILENAME = "output.wav"
def rec():
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
print("* 请讲话!")
frames = []
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
print("* 请闭嘴!")
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
wav2pcm.py
import os
def wav2pcm(wav_file):
# 假设 wav_file = "音频文件.wav"
# wav_file.split(".") 得到["音频文件","wav"] 拿出第一个结果"音频文件" 与 ".pcm" 拼接 等到结果 "音频文件.pcm"
pcm_file = "%s.pcm" %(wav_file.split(".")[0])
# 执行转换
os.system("ffmpeg -y -i %s -acodec pcm_s16le -f s16le -ac 1 -ar 16000 %s"%(wav_file,pcm_file))
return pcm_file
main.py
import record
import wav2pcm
from aip import AipSpeech
#百度语音的三个参数
APP_ID = "*"
API_KEY = "*"
SECRET_KEY = "*"
#录音
record.rec()
#wav转pcm
wav2pcm.wav2pcm("output.wav")
#读取pcm文件
with open("output.pcm","rb") as fp:
file_context = fp.read()
print("识别中...")
#调用百度语音API进行识别
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
res = client.asr(file_context,"pcm",16000,{'dev_pid':1536,})
#打印结果
#print(res['err_msg'])
print(res['result'])